This article is a technical deep-dive into Zidian, a hardware acceleration engine integrated into the Geehy G32R501 MCU.
1. Background
In traditional embedded development, if we need to run computationally intensive tasks on a small MCU, the conventional approaches are:
- Manual optimization using library functions or handwritten assembly.
- At the hardware design level, using additional peripherals or coprocessors (e.g., crypto, DSP) to accelerate specific functions.
But what if performance demands become increasingly stringent, and you don’t want to sacrifice the broad support of the Arm ecosystem? This is where “Custom Instructions” (or custom acceleration units) make their grand entrance:
- Flexibility: Allows you to “write” frequently used algorithm instructions into the CPU based on application needs, operating on processor registers with extremely low latency.
- Ecosystem Compatibility: No need for heavy modifications to the compiler or debugger; it maintains seamless integration with existing Arm tools.
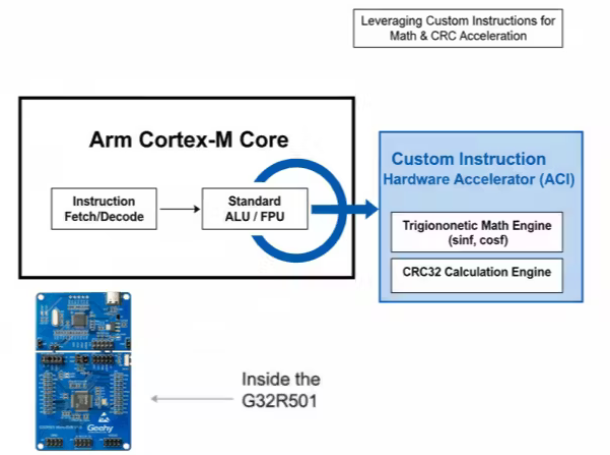
Zidian is precisely such an “acceleration engine” built on the G32R501 MCU, based on the Arm Custom Instructions (ACI) mechanism. Its primary goal is to dramatically boost computational power, reducing operations that would originally take tens or even hundreds of instructions down to just a few.
2. A Must-Talk: ACI, the Gateway to Hardware Customization
2.1 The “Past and Present” of ACI
ACI, which stands for Arm Custom Instructions, allows chip manufacturers to define custom data processing instruction sets on processors like the Cortex-M33, Cortex-M55, and Cortex-M52.
The traditional approach also involved hardware acceleration through the “Coprocessor Interface,” but it often required independent management of registers and memory access, making it suitable for batch processing or background execution scenarios.
ACI, on the other hand, operates closer to the CPU register pipeline, performing specific operations in a “tightly-coupled” manner, which is ideal for short-cycle, high-frequency computational needs.
In simple terms, ACI opens a door for MCUs to “deeply customize instructions” while preserving the standard Arm ecosystem and providing more fine-grained, instruction-level optimization.
2.2 How ACI is Implemented
At the hardware level, Arm reserves a portion of the coprocessor instruction encoding space for manufacturers to implement their own operations:
- Instruction Decode Stage: The CPU internally checks if the instruction belongs to a specific coprocessor number. If it’s related to ACI, it’s handed over to a “custom data path” for computation.
- Data Read/Write: The CPU reads the required registers (integer or floating-point) and sends the data to the ACI hardware module.
- Result Write-back: The result is then written back to a CPU register. If supported, certain flags in the APSR (Application Program Status Register), like NZCV, can also be updated at this stage.
2.3 ACI Instruction Style
In the Armv8-M architecture, ACI instructions typically appear in forms like CXn or VCXn:
- The
CX prefix usually corresponds to integer instructions.
- The
VCX prefix usually corresponds to floating-point (FPU) or vector (MVE) operations.
n can be 1, 2, 3, etc., indicating the number of input registers.- This can be followed by
A for accumulate mode or D for double-register/double-precision.
The instruction is followed by:
- Coprocessor # (the coprocessor number).
- Destination (the destination register).
- Source (the source register(s)).
- Immediate data value (which can be considered the instruction’s unique ID or sub-opcode).
Engineers simply need to use a compiler option, such as -mcpu=cortex-m52+cdecp0, to inform the toolchain: “I will be using coprocessor 0 for my custom instructions.”
Then, we can write intrinsic-like functions in C:
// Example in C, with English comments
uint32_t custom_operation(uint32_t input)
{
// Coprocessor number=0, immediate=0, e.g. simple operation
return __arm_cx1(0, input, 0);
}
This seemingly ordinary C function, after compilation, will generate a CX1-form custom instruction, which is ultimately executed by the ACI path in hardware. This is the charm of ACI: it adheres closely to the standard toolchain while enabling highly specific hardware acceleration.
2.4 Enter Zidian
With an understanding of ACI, we can now see how Zidian works:
In the G32R501, Zidian encapsulates common mathematical computations (like sin, cos, atan, sqrt, and even some CRC/FFT-related operations) as “dedicated instructions.” This allows the application layer to invoke these custom instructions simply by calling functions provided in zidian_math.h.
In principle, Zidian leverages the ACI capability of the Cortex-M architecture, combines it with its proprietary coprocessor ID, and wraps it into a series of intrinsics like __arm_cxX().
3. Zidian: The “Power-Up” in the Geehy Family
3.1 What Operations Can Zidian Accelerate?
For the G32R501, Zidian provides acceleration for typical integer and floating-point operations:
Integer (ICAU - Integer Custom Acceleration Unit):
- SIMD-related operations (e.g., complex multiplication, FFT)
- CRC algorithm acceleration
- Some special bitwise operations
Floating-Point (FCAU - Floating-point Custom Acceleration Unit):
- Trigonometric functions like sin, cos, atan, atan2
- Square root (
sqrtf32)
- Division, complex number ratios, etc.
In the header file zidian_math.h, you will find functions like:
__sinpuf32()__cos()__atan2puf32()__sqrtf32()__divf32()
Behind these seemingly normal functions lies Zidian's encapsulation of ACI, allowing developers to use them seamlessly.
In the header file zidian_cde.h, you can see all the instructions supported by the G32R501:
// CX2
#define __tas(x) __arm_cx2(0x0, x, 0x1)
#define __rstatus(x) __arm_cx2(0x0, x, 0x2)
#define __wstatus(x) __arm_cx2(0x0, x, 0x3)
#define __neg(x) __arm_cx2(0x0, x, 0x4)
// CX2A
#define __crc8l(y, x) __arm_cx2a(0x0, y, x, 0x8)
#define __crc16p1l(y, x) __arm_cx2a(0x0, y, x, 0x9)
#define __crc16p2l(y, x) __arm_cx2a(0x0, y, x, 0xa)
#define __crc32l(y, x) __arm_cx2a(0x0, y, x, 0xb)
#define __crc8h(y, x) __arm_cx2a(0x0, y, x, 0xc)
#define __crc16p1h(y, x) __arm_cx2a(0x0, y, x, 0xd)
#define __crc16p2h(y, x) __arm_cx2a(0x0, y, x, 0xe)
#define __crc32h(y, x) __arm_cx2a(0x0, y, x, 0xf)
// CX2DA
#define __tast(y, x) __arm_cx2da(0x0, y, x, 0x40)
// CX3
#define __sh1add(x1, x2) __arm_cx3(0x0, x1, x2, 0x8)
#define __sh1addi(x1, x2) __arm_cx3(0x0, x1, x2, 0x18)
#define __sh1addexh(x1, x2) __arm_cx3(0x0, x1, x2, 0xa)
#define __sh1addexhi(x1, x2) __arm_cx3(0x0, x1, x2, 0x1a)
#define __sh1addexl(x1, x2) __arm_cx3(0x0, x1, x2, 0xb)
#define __sh1addexli(x1, x2) __arm_cx3(0x0, x1, x2, 0x1b)
#define __sh1sub(x1, x2) __arm_cx3(0x0, x1, x2, 0xc)
#define __sh1subi(x1, x2) __arm_cx3(0x0, x1, x2, 0x1c)
#define __sh1subexh(x1, x2) __arm_cx3(0x0, x1, x2, 0xe)
#define __sh1subexhi(x1, x2) __arm_cx3(0x0, x1, x2, 0x1e)
#define __sh1subexl(x1, x2) __arm_cx3(0x0, x1, x2, 0xf)
#define __sh1subexli(x1, x2) __arm_cx3(0x0, x1, x2, 0x1f)
// CX3D
#define __hstas(x1, x2) __arm_cx3d(0x0, x1, x2, 0x20)
#define __hstsa(x1, x2) __arm_cx3d(0x0, x1, x2, 0x21)
#define __lstas(x1, x2) __arm_cx3d(0x0, x1, x2, 0x22)
#define __lstsa(x1, x2) __arm_cx3d(0x0, x1, x2, 0x23)
#define __max(x1, x2) __arm_cx3d(0x0, x1, x2, 0x25)
// CX3DA
#define __hbitsel(y, x1, x2) __arm_cx3da(0, y, x1, x2, 0x2)
// VCX2
#define __rd_scr(x) __arm_vcx2_u32(0x0, x, 0x6)
#define __wr_scr(x) __arm_vcx2_u32(0x0, x, 0x7)
...
For example, with the sinf function:
- When Zidian is enabled, the relevant
vcx instruction will be called.
- When Zidian is disabled, Arm’s standard library
hardfp_sinf function is used.
3.2 Tips for Using Zidian
- Enable ACI in the compiler:
- MDK-ARM: Add
-mcpu=cortex-m52+cdecp0.
- IAR: Add
--cdecp=0 in Extra Options.
- In preprocessor macros, define
__ZIDIAN_FCAU__ (if you need to replace the floating-point library functions).
- In your C code,
#include "zidian_math.h" and then freely call sinf(), cosf(), sqrtf(), atan2f(), etc.
After compilation, once the macro switch and instruction support are detected, the compiler will replace these standard functions with the Zidian custom instruction versions.
4. Let’s Benchmark: Before and After Acceleration
Now, it’s time to see the results. We’ll design a scenario to compare the execution time with and without Zidian.
4.1 Designing a “Complex” Test Driver
“Complex” here means repeatedly calling various functions within a large loop. When a function is called thousands or tens of thousands of times, even a tiny optimization can lead to a significant time difference. CRC and floating-point operations (sinf/cosf/sqrtf/atanf) are common in embedded systems, so this example will clearly demonstrate the performance gap.
We place the code in the G32R501's ITCM (Instruction Tightly-Coupled Memory) region and use the DWT (Data Watchpoint and Trace) cycle counter to measure the number of execution cycles.
The overall approach includes:
test_data[] is used for CRC32 calculation.float_data[] stores radian values from 0 to FLOAT_COUNTS-1.- In a loop, we call
dsp_crc32_test() and dsp_trig_test() respectively, using the GET_DWT_CYCLE_COUNT() macro to record the cycle counts before and after execution.
- Finally, we print the computation time and results to observe the differences.
4.2 Reference Code
The following is a complete example file, zidian_ex1_math.c, which you can use directly.
- The beginning of the file includes relevant headers like
driverlib and zidian_math.h.
- The code uses the
GET_DWT_CYCLE_COUNT() macro to simplify the measurement process.
dsp_crc32_test() and dsp_trig_test() will use either the hardware or pure software logic based on the defined macro.
Please note that the example uses SECTION_DTCM_DATA to place arrays in DTCM (Data Tightly-Coupled Memory) to reduce access latency. In a real project, you can place them in a suitable memory region as needed.
//
// Globals
//
SECTION_DTCM_DATA
volatile uint32_t dwtCycleCounts[2];
// Define test scale
#define TEST_SIZE 512
#define FLOAT_COUNTS 5000
// CRC32 constants
#define CRC32_POLY 0x04C11DB7U
#define CRC32_INIT 0xFFFFFFFFU
#define CRC32_XOROUT 0xFFFFFFFFU
// Global arrays (placed in DTCM)
SECTION_DTCM_DATA
static uint8_t test_data[TEST_SIZE];
SECTION_DTCM_DATA
float float_data[FLOAT_COUNTS];
// Function declarations
uint32_t dsp_crc32_test(const uint8_t *data, uint32_t length);
float dsp_trig_test(void);
//
// Main
//
void example_main(void)
{
printf("\nG32R501 EVAL zidian test!\n");
#if defined(__ZIDIAN_FCAU__)
printf("Zidian: ENABLED (Hardware Acceleration)\n");
#else
printf("Zidian: DISABLED (Pure Software)\n");
#endif
//
// Initialize test data
//
for(int i = 0; i < TEST_SIZE; i++)
{
test_data[i] = (uint8_t)i;
}
for(int i = 0; i < FLOAT_COUNTS; i++)
{
// Simulate different radian values using (i / 180.0f) * PI
float_data[i] = (float)(i) / 180.0f * 3.1415926f;
}
//
// Test
//
// 1) Measure CRC32
uint32_t crcResult;
GET_DWT_CYCLE_COUNT(dwtCycleCounts[0],
crcResult = dsp_crc32_test(test_data, TEST_SIZE));
// 2) Measure trigonometric functions test
volatile float trigResult = 0.0f;
GET_DWT_CYCLE_COUNT(dwtCycleCounts[1],
trigResult = dsp_trig_test());
printf("CRC Cycles : %u\n", dwtCycleCounts[0]);
printf("Trig Cycles : %u\n", dwtCycleCounts[1]);
printf("CRC Value : 0x%X\n", crcResult);
printf("Trig Value : %.6f\n", trigResult);
//
// Loop
//
for(;;)
{
}
}
// The version used (hardware-accelerated or software) depends on the compiler macro
#if defined(__ZIDIAN_FCAU__)
//------------------------------
// Hardware version of CRC
//------------------------------
uint32_t zidian_crc32(const uint8_t *data, uint32_t length)
{
uint32_t crc = CRC32_INIT;
for(uint32_t i = 0; i < length; i++)
{
// Dedicated Zidian instruction
crc = __crc32l(crc, data[i]);
}
crc ^= CRC32_XOROUT;
return crc;
}
#else
//------------------------------
// Pure software version of CRC
//------------------------------
uint32_t zidian_crc32(const uint8_t *data, uint32_t length)
{
uint32_t crc = CRC32_INIT;
for(uint32_t i = 0; i < length; i++)
{
crc ^= ((uint32_t)data[i]) << 24;
for(int bit = 0; bit < 8; bit++)
{
if(crc & 0x80000000U)
crc = (crc << 1) ^ CRC32_POLY;
else
crc <<= 1;
}
}
crc ^= CRC32_XOROUT;
return crc;
}
#endif
// Floating-point test function
float dsp_trig_test(void)
{
volatile float result = 0;
for(int j = 0; j < FLOAT_COUNTS; j++)
{
// Continuously call various functions
result += sinf(float_data[j]);
result += cosf(float_data[j]);
result += sqrtf(float_data[j]);
result += atanf(float_data[j]);
// Call atanf again
result += atanf(float_data[j]);
}
return result;
}
4.3 Actual Test Results
With the code placed in ITCM RAM and run in a simulation environment, we collected the following benchmark data (from typical measurement results):
Zidian Disabled (Pure Software Mode):
- CRC Cycles : 114234
- Trig Cycles : 2522328
- CRC Value : 0×2F728526
- Trig Value : 46191.281250
Zidian Enabled (Hardware Acceleration Mode):
- CRC Cycles : 12319
- Trig Cycles : 1250023
- CRC Value : 0×2F728526
- Trig Value : 46191.285156
The results clearly show that after enabling Zidian, the CRC calculation time dropped from 114,234 cycles to just 12,319 cycles, a performance improvement of nearly 9 times. The floating-point test also saw its cycle count decrease from about 2.52 million to about 1.25 million, reducing the execution time by more than half.
It is also worth noting that the CRC results are identical in both modes, and the trigonometric results only show minor differences in the floating-point decimal places, demonstrating that Zidian does not compromise computational accuracy.
In summary, the Zidian hardware accelerator can greatly alleviate the performance pressure on the CPU when processing large-scale CRC and floating-point functions, giving the overall computing power of the G32R501 a significant leap. This is the essence of Zidian's appeal: providing a massive boost to your MCU’s computational power with almost no changes to your application logic.
5. Conclusion: Towards a New World of Efficiency and Elegance
Through the ACI interface, Zidian on the G32R501 opens a door to greater efficiency. Whether for CRC or trigonometric functions, by simply toggling a macro at compile time, you can offload the repetitive computational burden to the hardware, significantly reducing the main CPU’s workload. What’s even better is that all of this is achieved without you having to manually write tedious assembly code or compromise on accuracy—it’s a true “one-stop” acceleration solution.
Of course, Zidian's capabilities may extend beyond this. If your project heavily uses DSP-like computations, you can explore its potential further. After all, once you get a taste of the benefits of hardware acceleration, you’ll find that those once-troublesome performance bottlenecks might just be an __crc32l() or __arm_cx2(...) instruction away.
Reference Documents:
- arm-custom-instructions-wp.pdf
- arm-custom-instructions-without-fragmentation-whitepaper.pdf
- AN1132_G32R501 zidian Application Note V1.0.pdf