In precise motion control, magnetic angle sensors are ubiquitous. An advanced Magnetic Encoder is ideal for industrial servo systems, embodied robots, and intelligent automation equipment.

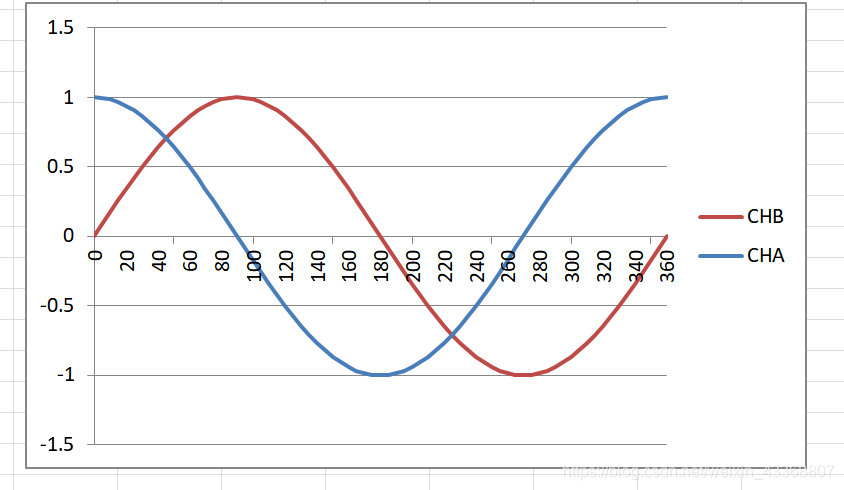
A magnetic sensor typically possesses two coils arranged at 90° to each other. These coils generate two output signals with a 90° phase difference:
- Channel A (e.g., CHA): Outputs a signal proportional to cos(θ)
- Channel B (e.g., CHB): Outputs a signal proportional to sin(θ)
Note: Here, θ represents the actual rotation angle of the magnet.
Converting the raw analog signals (U_A, U_B) from these sensors into a precise angle θ requires the arctan2 function.
While the math is theoretically simple, implementing it efficiently on a MCU has historically been a challenge.
Today, we compare the traditional software approach using CMSIS-DSP against a cutting-edge hardware solution found in the new Cortex-M52 based Encoder MCU - G32R430.
Voltage Signals
Mathematically, these two signals change with the angle as follows:
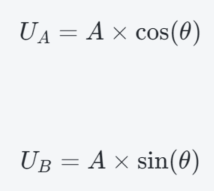
Assume A is the amplitude (generally treated as constant for simplicity).
Given the measured voltages U_A and U_B, how do we recover the angle θ?
Since we have both sine and cosine components, the angle can be uniquely determined using inverse trigonometric functions. The basic relationship is:
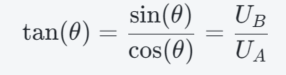

However, the standard arctan formula cannot distinguish the correct quadrant (e.g., it cannot tell the difference between 45° and 225°. This is why the arctan2 function is essential:

This function allows for accurate extraction of the angle in the full range (0°360° or −π∼π), regardless of the sign of the signals.
Why Must the Signals Be 90° Out of Phase?
Only when the two signals are perfectly orthogonal (90° out of phase) can you ensure that for any angle, the pair (sinθ, cosθ) is always unique and never simultaneously zero.
This guarantees:
- No dead zones
- Full angle coverage
The relationship between the signals and the angle can be visualized on a unit circle:
y (sin θ)
↑
| ● (Coordinate: cos θ, sin θ)
| /
| / angle θ
|/
◄──────────┼──────────► x (cos θ)
|
|
|
x-coordinate: corresponds to U_A (cosθ)
y-coordinate: corresponds to U_B (sinθ)
Angle θ: The angle between the vector and the positive x-axis.
The Traditional Software Approach (CMSIS-DSP)
For years, developers have relied on optimized software libraries like Arm’s CMSIS-DSP on Cortex-M/Cortex-A MCU/DSPs.
Let’s have a look of arm_atan2_f32.c to understand the computational cost.
The algorithm typically involves three heavy steps:
Step A: Quadrant Management
The CPU must perform multiple branching checks (if/else) to handle the signs of x and y and edge cases (like x=0). This consumes clock cycles and can disrupt the pipeline.
Step B: Floating Point Division
Before calculating the arc tangent, the ratio must be computed:
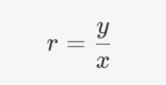
Floating-point division is one of the most expensive operations for a standard CPU core, taking significantly more cycles than addition or multiplication.
Step C: Polynomial Approximation
Since computers cannot inherently calculate “angles,” they use approximation algorithms (like Taylor series or Minimax approximation). The CMSIS-DSP implementation uses a 10th-order polynomial to achieve acceptable precision:
#define ATAN2_NB_COEFS_F32 10
static const float32_t atan2_coefs_f32[ATAN2_NB_COEFS_F32]={0.0f
,1.0000001638308195518f
,-0.0000228941363602264f
,-0.3328086544578890873f
,-0.004404814619311061f
,0.2162217461808173258f
,-0.0207504842057097504f
,-0.1745263362250363339f
,0.1340557235283553386f
,-0.0323664125927477625f
};
for(i=1; i<ATAN2_NB_COEFS_F32; i++) {
res = x*res + atan2_coefs_f32[ATAN2_NB_COEFS_F32-1-i];
}
The Cost:
Even with an optimized Cortex-M4 or M7, determining one angle requires:
- Expensive division.
- 10 multiply-accumulate operations for the polynomial.
- Multiple branch instructions.
From Software Approximations to MCU Precision: G32R430
A new generation of MCUs, Geehy’s G32R430, based on the Arm Cortex-M52 core, changes the game by integrating a Trigonometric Math Unit (TMU). The unit was defined & integrated by the excellent Geehy R&D team.
Let’s look at the specifications of this high-performance MCU:
- Core: Arm Cortex-M52 @ 128 MHz
- Accelerator: Integrated hardware TMU with native ATAN operation
- Analog: 12-Channels 16-bit 1MSPS ADC for ATAN data sampling, 4*Comparators for Photoelectric Encoder applications, advanced internal T-Sensor.
- Memory Architecture: No standard SRAM; instead uses 32 KB ITCM (Instruction) and 16 KB DTCM (Data)
- Low Power Consumption: Standby Consumption <1.5μA, Wake-up Time <32μs; Stop Consumption <8μA, Wake-up Time <20μs; Average Power Consumption @ 6000RPM: 62.3μA, 50% saving enabling a longer battery life.
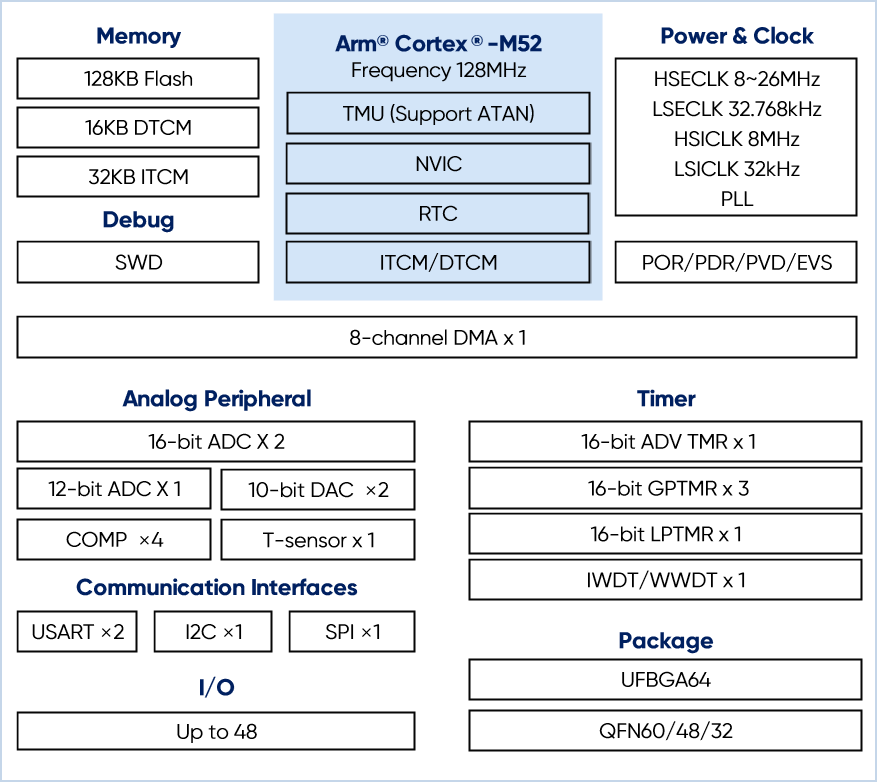
Instead of running the heavy C-code shown above, the arctan2 calculation is offloaded to the dedicated hardware unit.
⚡ Direct Hardware Acceleration
Streamlines the calculation pipeline by accepting two 16-bit ADC samples directly and returning a precise 32-bit Electrical Angle. No intermediate software formatting required.
🎯 Ultra-High Precision
Achieves an ATAN measurement precision of < 0.0001°. This eliminates the quantization errors often found in look-up table methods, ensuring silky-smooth motor rotation.
⏱️ Microsecond Latency
The dedicated hardware path reduces the encoder electrical angle output latency to < 1 μs. This near-instantaneous feedback is critical for high-frequency control loops.
📈 40% Faster Response
By offloading the heavy lifting to the TMU, the overall position loop response speed is improved by 40% compared to traditional software-based solutions.
G32R430 abandons traditional SRAM for ITCM and DTCM.
- Zero Latency: The CPU can fetch instructions (ITCM) and data (DTCM) at full core speed (128 MHz) without wait states.
- Predictability: The combination of TCM and TMU ensures that the angle calculation is not only fast but perfectly predictable, with no cache misses or bus contention.
| Feature | Software Approach (CMSIS-DSP) | Hardware Approach (Cortex-M52 TMU) |
|---|
| Method | Polynomial Approximation (10 coefficients) | Hardware Logic Gate Array (CORDIC or Look-up) |
| CPU Load | High (Math + Branching) | Near Zero (Offloaded) |
| Latency | High (dozens of cycles) | Ultra-Low (single digit cycles) |
| Precision | Limited by polynomial order | Native Hardware Precision |
| Code Size | Large (requires lookup tables & logic) | Tiny (single instruction) |
__
By utilizing the G32R430 with Hardware ATAN, encoder developers can eliminate the arm_atan2_f32 overhead entirely.
This frees up the 128 MHz CPU to focus on complex control algorithms, communication stacks, or safety checks, resulting in a system that is faster, more power-efficient, and more responsive.
🛠️ Ready-to-Deploy: Geehy’s 17-bit Absolute Encoder Reference Design
Geehy has released a comprehensive Magnetic Absolute Encoder Reference Solution.
Designed around the familiar ARM architecture, this turnkey solution is optimized for high-performance motion control applications.
⚡ High-Speed Processing
Designed for real-time responsiveness, the system completes the control loop in just 3 μs and finishes the complex angle compensation algorithm in 8 μs.
📏 Compact & Efficient
Fits perfectly into space-constrained designs with a compact 35mm footprint. It is also remarkably energy-efficient, boasting an average static power consumption of only 13 μA.
🌐 Broad Protocol Support
Seamlessly integrates with industrial standards, offering full support for efficient Tamagawa, BiSS-C, and SSI communication protocols.
🛡️ Robust Reliability & Safety
- Resolution: 17-bit single-turn resolution.
- Multi-turn: Supports up to 32-bit turn counting.
- Diagnostics: Built-in alarms for Battery Undervoltage, Over-temperature, and Over-speed conditions.
This solution is tailored for designers in Robotic Joints, Servo Control, and Elevator Systems who want to leverage the power and flexibility of the ARM MCU ecosystem to accelerate their product launch.
